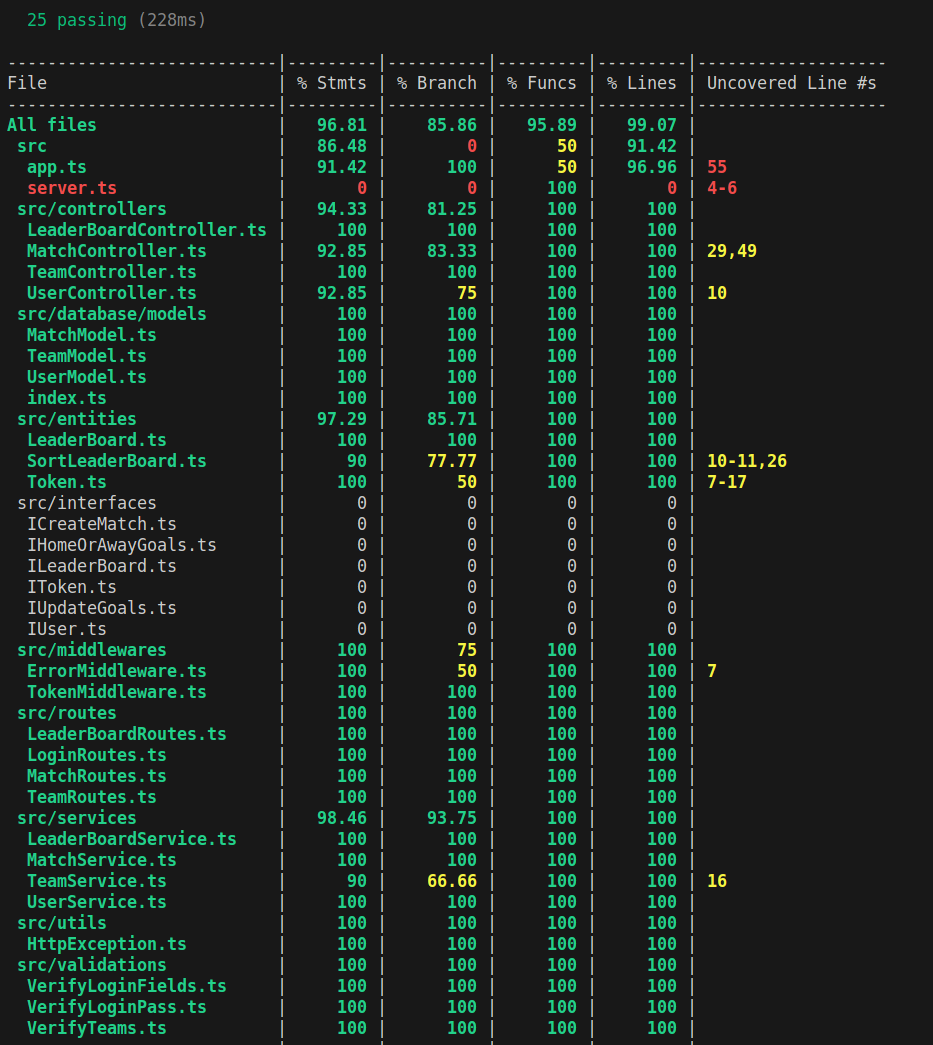
The datasets used can be found here:
Before train the model, We need to preprocess the raw dataset. We take EuroSense as example. EuroSense consist of a a single large XML file (21GB uncompressed for the high precision version), even though it is a multilingual corpus, we will use only the English sentences. The file can be filtered with the filter_eurosense() function inside preprocessing/eurosense.py file.
The EuroSense files contains sentences, with already tokenized text. Each annotation marks the sense for a word in text identified by the anchor attribute. Each annotation provides the lemma of the word it is tagging and the synset id.
<sentence id="0">
<text lang="en">It is vital to minimise the grey areas and [...] </text>
<annotations>
<annotation lang="en" type="NASARI" anchor="areas" lemma="area"
coherenceScore="0.2247" nasariScore="0.9829">bn:00005513n</annotation>
...
</annotations>
</sentence>
It is convenient to preprocess the XML in a single text file, replacing all the anchors with the corresponding lemma_synset. A line in the parsed dataset, from the example above, is
It is vital to minimise the grey area_bn:00005513n and [...]
We can run the parse.py script to obtain this parsed dataset.
python code/parse.py es -i es_raw.xml -o parsed_es.txt
Gensim implementation of Word2Vec and FastText are used to train the sense vectors. The train script is implemented in the train.py file. To start the training phase, run
python code/train.py parsed_es.txt -o sensembed.vec
For a complete list of options run python code/train.py -h
usage: train.py [-h] -o OUTPUT [-m MODEL] [--model_path SAVE_MODEL]
[--min-count MIN_COUNT] [--iter ITER] [--size SIZE]
input [input ...]
positional arguments:
input paths to the corpora
optional arguments:
-h, --help show this help message and exit
-o OUTPUT path where to save the embeddings file
-m MODEL model implementation, w2v=Word2Vec, ft=FastText
--model_path SAVE_MODEL
path where to save the model file
--min-count MIN_COUNT
ignores all words with total frequency lower than this
--iter ITER number of iterations over the corpus
--size SIZE dimensionality of the feature vectorsThe output should be in the Word2Vec format, where the vocab is composed of lemma_synset1 and the corresponding vector.
number_of_senses embedding_dimension
lemma1_synset1 dim1 dim2 dim3 ... dimn
lemma2_synset2 dim1 dim2 dim3 ... dimn
The evaluation consists of measuring the similarity or relatedness of pairs of words. Word similarity datasets (WordSimilarity-353) consists of a list of pairs of words. For each pair we have a score of similarity established by human annotators
Word1 Word2 Gold
-------- -------- -----
tiger cat 7.35
book paper 7.46
computer keyboard 7.62
The scoring algorithm inside score.py computes the cosine similarity between all the senses for each pair of word in the word similarity datasets.
for each w_1, w_2 in ws353:
S_1 <- all sense embeddings associated with w_1
S_2 <- all sense embeddings associated with w_2
score <- -1.0
For each pair s_1 in S_1 and s_2 in S_2 do:
score = max(score, cos(s_1, s_2))
return score
where cos(s_1, s_2) is the cosine similarity between vector s_1 and s_2.
Now we check our scores against the gold ones in the dataset. To do so, we calculate the Spearman correlation between gold similarity scores and cosine similarity scores.
Word1 Word2 Gold Cosine
-------- -------- ----- ------
tiger cat 7.35 0.452
book paper 7.46 0.784
computer keyboard 7.62 0.643
Spearman([7.35, 7.46, 7.62], [0.452, 0.784, 0.643]) = 0.5
The score can be computed by running the following command
python code/score.py sensembed.vec resources/ws353.tab